| 日期 | 内核版本 | 架构 |
|---|---|---|
| 2022-08-7立秋 | Linux5.4.200 | X86 & arm |
Linux物理内存模型
前言
本文是Linux内存管理系列文章的第一篇,先对一些常见概念有一个基本的认知。
提问环节:
- Linux支持哪几种内存模型?
- Multiprocessors系统设计内存架构的两种模式?
- Linux内存有哪三大结构?
去本文中找答案吧!
Linux内存模型
所谓的内存模型,是从CPU的角度来观察物理内存的分布,而CPU 通过总线去访问内存。
Linux kernel支持3种内存模型:
- Flat Memory Model
- Discontiguous Memory Model
- Sparse Memory Model
在经典的**平坦内存模型(Flat Memory Model)**中,物理地址是连续的,页也是连续的,每个页大小也是一样的。每个页有一个结构 struct page 表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的 struct page 结构。
当存在多个CPU时分布在总线的一侧,所有内存组成的整体在内存的另一侧,所有的CPU访问内存都要经过总线,而且距离都相同。这就是我们熟悉的对称多处理器SMP(Symmetric multiprocessing),如下左图所示。这种模式成为UMA(uniform memory access)。针对嵌入式系统,一般采用UMA模式。不过这种模型缺点很明显,就是所有数据都要经过同一个总线,总线会成为瓶颈。
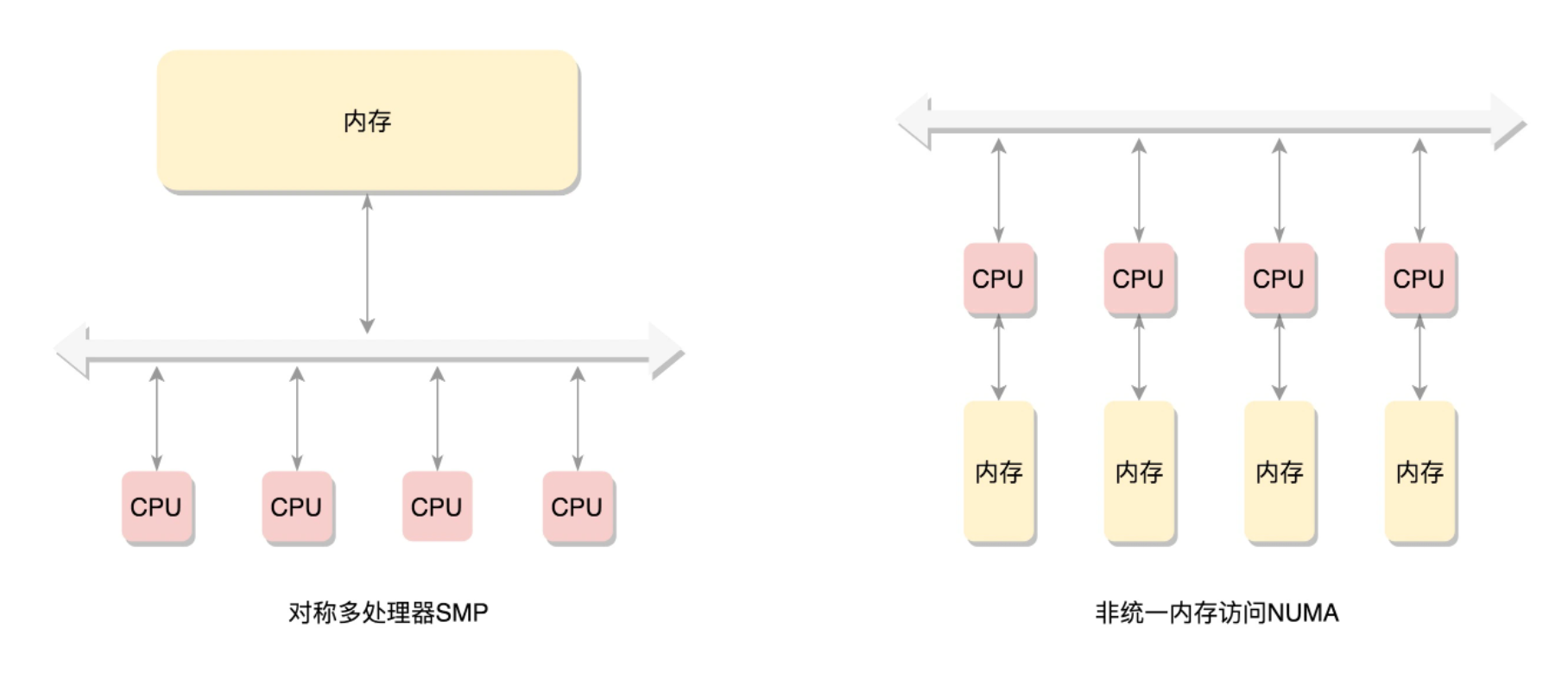
为了提高性能和可拓展性,有了另一个模式NUMA(Non-uniform memory access),非一致内存访问。如上右图所示。仔细观察内存的划分,不再是一整块,而是每个CPU有各自的内存。CPU访问本地内存不需要经过总线,CPU+本地内存成为一个NUMA节点。如果本地不够用,就要通过总线去其他NUMA节点申请内存,时间上肯定会久一些。、
NUMA往往是非连续内存模型(Discontiguous Memory Model)。内存被分成了多个节点,每个节点再被分成一个一个的页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,页号也就不再连续了。注意,非连续内存模型不是NUMA模式的充分条件,一整块内存中物理内存地址也可能不连续。
当memory支持hotplug,**稀疏内存模型(Sparse Memory Model)**也应运而生。sparse memory最终可以替代Discontiguous memory的,这个替代过程正在进行中。
物理内存三大结构
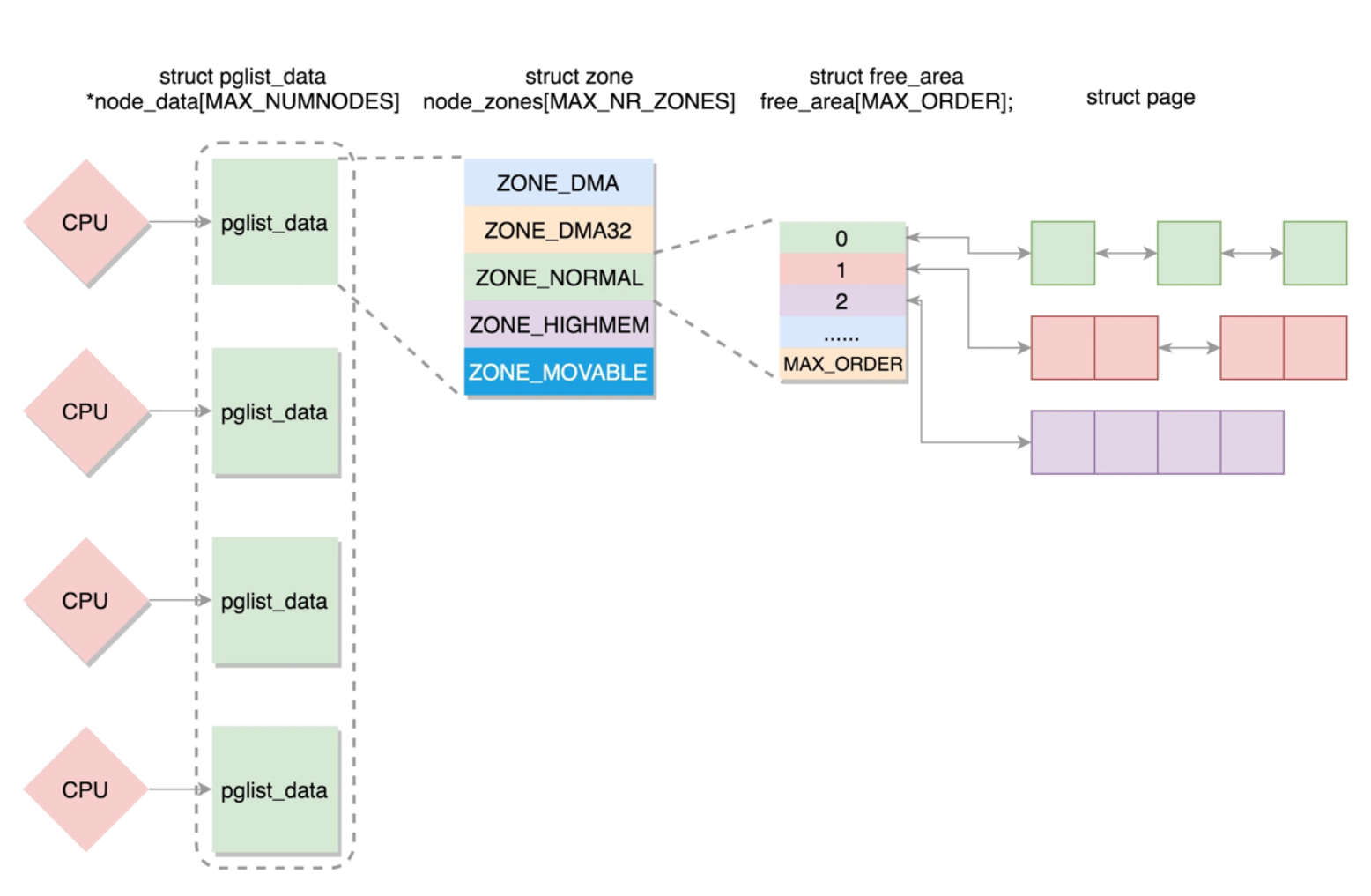
Node
NUMA中CPU加本地内存成为一个Node,UMA中只有一个Node。
Node在Linux中用typedef struct pglist_data pg_data_t表示。
https://elixir.bootlin.com/linux/v5.4.200/source/include/linux/mmzone.h#L698
主要成员变量包括:
- node_id;每一个节点都有自己的 ID:
- node_mem_map 就是这个节点的 struct page 数组,用于描述这个节点里面的所有的页;
- node_start_pfn 是这个节点的起始页号;
- node_spanned_pages 是这个节点中包含不连续的物理内存地址的页面数;
- node_present_pages 是真正可用的物理页面的数目。
- node_zones: 每一个节点分成一个个区域 zone,放在node_zones数组里。
- nr_zones 表示当前节点的区域的数量
- node_zonelists 是备用节点和它的内存区域的情况。当本地内存不够用,就要通过总线去其他NUMA节点觅食。
1 | typedef struct pglist_data { |
整个内存被分为多个节点,pglist_data放在一个数组中。
1 | struct pglist_data *node_data[MAX_NUMNODES] __read_mostly; |
Zone
每一个Node分成多个zone,放在数组 node_zones 中,大小为 MAX_NR_ZONES。我们来看区域的定义。
1 | enum zone_type { |
| 管理内存域 | 描述 |
|---|---|
| ZONE_DMA | 对于不能通过ZONE_NORMAL进行DMA访问的,需要预留这部分内存用于DMA操作 |
| ZONE_DMA32 | 用于低于4G内存访问 |
| ZONE_NORMAL | 直接映射区,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射 |
| ZONE_HIGHMEM | 高端内存区,对于 32 位系统来说超过 896M 的地方,对于 64 位没必要有的一段区域 |
| ZONE_MOVABLE | 可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片 |
| ZONE_DEVICE | 为支持热插拔设备而分配的Non Volatile Memory非易失性内存 |
| __MAX_NR_ZONES | 充当结束标记, 在内核中想要迭代系统中所有内存域, 会用到该常量 |
Zone的结构体如下(https://elixir.bootlin.com/linux/v5.4.200/source/include/linux/mmzone.h#L417)
1 | struct zone { |
主要的变量有:
- zone_start_pfn 表示属于这个 zone 的第一个页
- spanned_pages = zone_end_pfn - zone_start_pfn;根据注释: spanned_pages is the total pages spanned by the zone, including
holes, which is calculated as.指的是不管中间有没有物理内存空洞,直接最后的页号减去起始的页号,简单粗暴. - present_pages = spanned_pages - absent_pages(pages in holes);present_pages 是这个 zone 在物理内存中真实存在的所有 page 数目
- managed_pages = present_pages - reserved_pages,也即 managed_pages 是这个 zone 被伙伴系统管理的所有的 page 数目.
- per_cpu_pageset用于区分冷热页.
注: 如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)
Page
page是组成物理内存的基本单位.用struc_page表示.
https://elixir.bootlin.com/linux/v5.4.200/source/include/linux/mm_types.h#L68
1 | struct page { |
谦哥定眼一看,page结构真的复杂!由于一个物理页面有很多使用模式,所以这里有很多union.
模式1: 从一整页开始用
- 一整页内存直接和虚拟地址空间建立映射的称为匿名页(Anonymous Page)
- 一整页内存先关联文件再和虚拟地址空间建立映射的称为内存映射文件(Memory-mapped File)
此时Union中的变量为:
- struct address_space *mapping 就是用于内存映射,如果是匿名页,最低位为 1;如果是映射文件,最低位为 0;
- pgoff_t index 是在映射区的偏移量;
- atomic_t _mapcount,每个进程都有自己的页表,这里指有多少个页表项指向了这个页;
- struct list_head lru 表示这一页应该在一个链表上,例如这个页面被换出,就在换出页的链表中;
- compound 相关的变量用于复合页(Compound Page),就是将物理上连续的两个或多个页看成一个独立的大页。
模式2: 仅需分配小块内存
如果某一页是用于分割成一小块一小块的内存进行分配的使用模式,则会使用 union 中的以下变量:
- s_mem 是已经分配了正在使用的 slab 的第一个对象;
- freelist 是池子中的空闲对象;
- rcu_head 是需要释放的列表。
1 |
|
总结
-
Linux kernel支持3种内存模型:
- Flat Memory Model
- Discontiguous Memory Model
- Sparse Memory Model
-
Multiprocessors系统设计内存架构的两种模式
- UMA
- NUMA
-
Linux物理内存的三大结构
- Node: CPU和本地内存组成Node, 用 struct pglist_data 表示,放在一个数组里面。
- Zone: 每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面
- Page: 每个区域分为多个页,每一页用 struct page 表示